In this post, we are going to examine ranking of stories and comments on Reddit and Reddit new voting system, basing on data from the 2018.
Firstly, we will focus on how the Reddit stories ranking works. In the second part, we will concentrate on comment ranking which is being formed differently from that of stories (excepting Hacker News). Reddit`s comment ranking algorithms are quite interesting to dig into.
Examining the story ranking code
Being open-sourced, Reddit has its code freely available. It is implemented in Python and their sorting algorithms are implemented in Pyrex, which is a language of the Python C extensions. Reddits is using Python because of its speed. The default story algorithm called the hot ranking is implemented in the following way:

In mathematical notation the hot algorithm looks like this:

Concerning the submission time
Besides the Reddit upvote algorithm, the submission time should be taken into account when we talk about the story ranking.
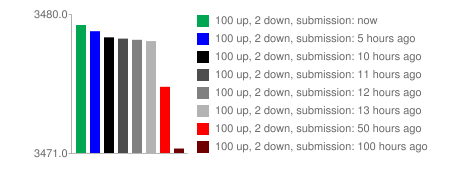
The submission time has a great effect related to story ranking: new stories will get higher score than older ones.
The score will not decline with time, but newer posts will have higher score than older ones.
This approach is different from the one used in Hacker News, where the score decreases over time.
Here is a visualization of the score for a story that has same amount of up and downvotes, but different submission time:
The logarithm scale
Reddit’s hot ranking uses the logarithm function to weight the first votes higher than the rest. Generally this applies:
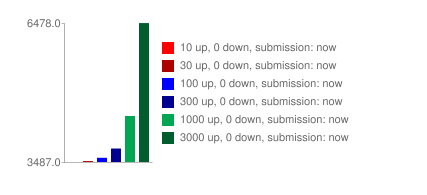
The first 10 upvotes have the same weight as the next 100 upvotes which have the same weight as the next 1000 etc…
Here is an illustration:

Without logarithm scale the score:
The influence of downvotes
Reddit voting system includes downvotes. This can be visualized in the following way:

It reasonably influences the score, especially if we talk about the stories which have a lot of upvotes and downvotes. Their Reddit rating will be lower than that of the stories with only Reddit likes. This can explain why those cue stories with pets (and other not controversial content) get such high rating. Another way to get high rating is to buy Reddit upvotes or simply get free Reddit upvotes by posting kittens or using Reddit upvote exchange.
The conclusion regarding the story raking can be the following
Submission time is a very important parameter, generally newer stories will rank higher than older;
The first 10 upvotes count as high as the next 100. E.g. a story that has 10 upvotes and a story that has 50 upvotes will have a similar ranking;
Controversial stories that get similar amounts of upvotes and downvotes will get a low ranking compared to stories that mainly get upvotes.
How Reddit comments rating system works
In a nutshell, Reddit traffic works in a following way:
The use of hot algorithm in comments would not be the wisest decision as it is significantly biased towards the older comments;
It is more reasonable to give the highest score to the best comments, regardless of the submission time;
A mathematical solution for it is called “Wilson score interval”. Wilson’s score interval can be made into “the confidence sort”;
The confidence sort regards the vote counting as a statistical sampling of a hypothetical full vote by everyone;
How Not To Sort By Average Rating outlines the confidence ranking in higher detail, definitely recommended reading!
Digging into the comment ranking code
The confidence sort algorithm is implemented in _sorts.pyx., here you can see their Pyrex implementation rewritten (do also note that their caching optimization has been removed):

The confidence sort uses Wilson score interval and the mathematical notation looks like this:
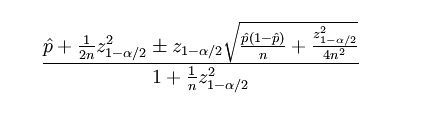
In the above formula the parameters are defined in a following way:
p is the observed fraction of positive ratings;
n is the total number of ratings;
zα/2 is the (1-α/2) quantile of the standard normal distribution.
Let's summarize the above-said in a nutshell
The confidence sort treats the vote count as a statistical sampling of a hypothetical full vote by everyone;
The confidence sort gives a comment a provisional ranking that it is 85% sure it will get to;
The more votes, the closer the 85% confidence score gets to the actual score;
Wilson’s interval has good properties for a small number of trials and/or an extreme probability.
Here you can see an example of using confidence sort for rating the comments:
“If a comment has got one upvote and no downvotes, its score will be 100% positive, but as it doesn`t have a lot of data, the system will put it lower in ranking. But if it has 10 upvotes and only 1 downvote, the system might have enough confidence to place it above something with 40 upvotes and 20 downvotes — figuring that by the time it’s also gotten 40 upvotes, it’s almost certain it will have fewer than 20 downvotes. And the best part is that if it’s wrong (which it is 15% of the time), it will quickly get more data, since the comment with less data is near the top. This is how Reddit upvote downvote system works”.
Does the submission time has any influence? It doesn't!
The great thing about the confidence sort is that submission time is irrelevant (much unlike the hot sort or Hacker News’s ranking algorithm). Comments are ranked by confidence and by data sampling — — i.e. the more votes a comment gets the more accurate its score will become.
How would it be depicted by a graph?
Let’s visualize the confidence sort and see how it ranks comments.We can show by the following example:

The confidence sort does not care about how many votes a comment have received, but about how many upvotes it has compared to the total number of votes and to the sampling size!
Application outside of ranking
Wilson’s score interval has applications outside of ranking. Let's consider three applications of it:
Detect spam/abuse: What percentage of people who see this item will mark it as spam?
Create a “best of” list: What percentage of people who see this item will mark it as “best of”?
Create a “Most emailed” list: What percentage of people who see this page will click “Email”?
In order to use Wilson's interval we need:
the total number of ratings/samplings;
the positive number of ratings/samplings
It is quite surprising that a lot of famous websites still don't use Wilson's interval while applying less efficient ways of content ranking. This includes billion dollar companies like Amazon.com, which define Average rating = (Positive ratings) / (Total ratings).
Add new comment